 Analyse et conception objet - Séance n°7 : Modélisation UML
Analyse et conception objet - Séance n°7 : Modélisation UML
Généralités
UML est un langage de modélisation graphique qui simplifie la création et la représentation de logiciels objets. Il vous permet de comprendre et de raisonner sur le logiciel que vous souhaitez créer et il permet de préparer son architecture avant d’en débuter la programmation.
UML est apparu dans les années 90 et résultait de la convergence de trois langages permettant d’organiser les codes objet:
OMT (représentation graphique)
OOD (concept de packages)
OOSE (cas d’utilisation)
UML a été adopté en 1997 par l”Object Management Group (OMG) comme langage de modélisation des systèmes d’information à objets. UML2 a été adopté en 2005 par l’OMG. Ce dernier est organisé autour des 14 diagrammes. L’idée consiste à n’utiliser que les diagrammes dont on a besoin pour notre application, et on peut les créer dans n’importe quel ordre (l’idéal est d’ailleurs d’en créer plusieurs en parallèle et de les modifier en passant de l’un à l’autre). UML est donc un langage assez souple.
Nous allons maintenant introduire ces diagrammes à l’aide d’un exemple de développement d’application.
Analyse des besoins
Quand on développe une application, on débute par l’analyse des besoins, c’est-à-dire que l’on souhaite trouver les acteurs de l’application (qui va s’en servir) et leurs buts (pour quoi faire). Ici, on s’attache aux « grandes fonctionnalités », pas aux détails. De plus, on ne s’intéresse pas à la manière de s’y prendre pour réaliser ces buts (le « comment faire ») : cette partie viendra plus tard. L’analyse des besoins passe en général par des entretiens avec les acteurs (souvent les clients qui ont commandé le logiciel).
Pour mener à bien cette phase, UML propose un diagramme de cas d’utilisation et un diagramme de séquences qui sont particulièrement utiles.
Diagramme de cas d'utilisation (Use case diagram)
Ce type de diagramme montre les activités d’un acteur et son interaction avec le système.
Considérons une application de jeu de rôles. On a un joueur qui doit affronter des monstres (Orc, Gobelins, Elfs) dans un monde virtuel. Disséminés dans ce dernier, il existe des coffres permettant de remonter les points de vie ou les munitions du joueur. L’objectif de ce dernier est, problématique Kafkaïenne, d’atteindre le château.
Le diagramme ci-dessous est un diagramme de cas d’usage d’une telle application. Les explications sont indiquées en dessous de ce dernier.
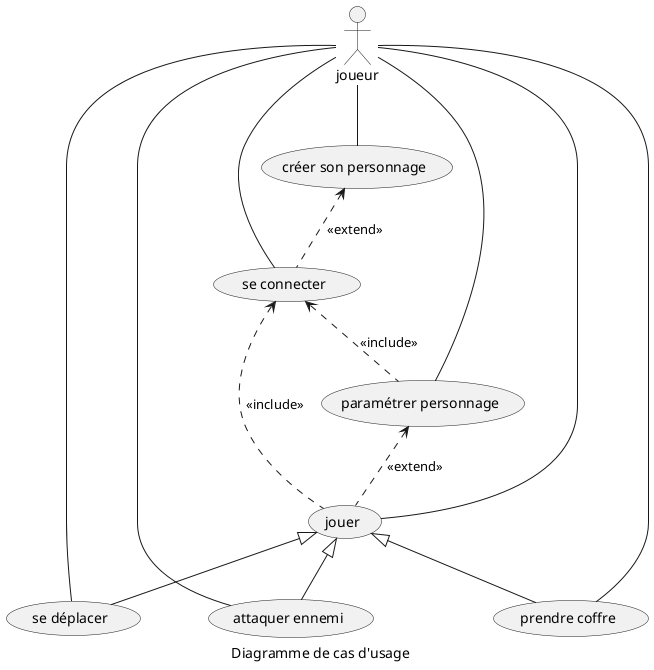
Tout d’abord, on spécifie l’acteur qui va utiliser l’application (ici, le joueur), qui est représenté sous la forme d’un petit bonhomme. Les ellipses représentent les actions possibles de l’acteur (on dit aussi les cas d’usage ou les cas d’utilisation). Pour symboliser que l’acteur réalise ces actions, on trace des arêtes entre l’acteur et toutes les actions possibles. On note que l’on évite au maximum les détails. Par exemple, l’action « se déplacer » peut être utilisée par le joueur pour se mouvoir dans le jeu afin d’atteindre le château mais également pour fuir un ennemi. Les ellipses représentent les « grandes » actions possibles.
Certaines actions ne peuvent avoir lieu qu’après en avoir nécessairement réalisé d’autres. C’est ce qu’indiquent les flèches en pointillés labélisées <<include>>. Par exemple, la flèche entre l’action « se connecter » et l’action « jouer » indique que, pour pouvoir jouer au jeu, il faut d’abord s’être connecté. Les flèches en pointillés labélisées <<extend>> représentent des actions qui peuvent être exécutées éventuellement avant d’autres mais qui ne sont pas nécessairement exécutées : par exemple, la flèche entre « jouer » et « paramétrer personnage » indique que le joueur peut, s’il le souhaite, paramétrer son personnage avant de jouer, mais qu’il peut jouer même s’il n’a pas paramétré son personnage. La flèche « extend » entre la connexion et la création du personnage s’interprète de la manière suivante : quand le joueur exécute l’application, il peut demander à se connecter. S’il a déjà créé son personnage, on ne lui demandera pas d’en créer un nouveau. En revanche, s’il n’en a pas encore créé, on va lui demander d’en créer un pour pouvoir se connecter. Lors d’une exécution de l’application, la création du personnage n’est donc pas nécessairement réalisée. Mais si elle l’est, elle le sera avant la connexion. Enfin, les flèches en traits pleins avec les triangles blancs indiquent des sous-cas, de la spécialisation (en quelque sorte, c’est une forme d’héritage) : ici, on dit que les actions que l’on peut mener quand on joue sont « se déplacer », « attaquer » et « prendre coffre ».
Pour résumer ce que traduit le diagramme ci-dessus, on peut dire qu’un joueur doit commencer par se connecter au jeu, après avoir, éventuellement, créé un personnage. Une fois ces actions réalisées, il peut jouer, après avoir, éventuellement, paramétré son personnage. Enfin, une fois le jeu lancé, il consiste, pour le joueur, à se déplacer sur l’espace de jeu, à prendre le contenu des coffres à côté desquels il passe et à attaquer des ennemis.
Résumé des symboles du diagramme de cas d'usage
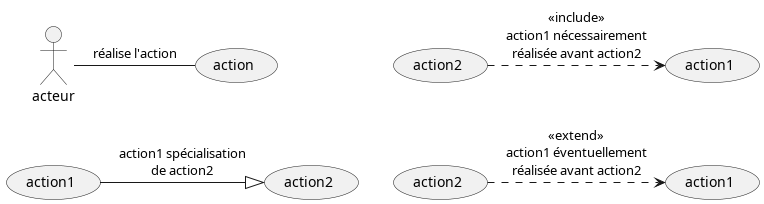
Notez qu’il existe d’autres symboles dans les diagrammes de cas d’usage, mais ceux indiqués ci-dessus sont les principaux.
Exercice 1 : Diagramme de cas d'usage de ma petite entreprise 
Reprenez l’exercice sur l’entreprise de restauration en ligne de la séance précédente et créez le diagramme UML de cas d’usage correspondant. Vous pouvez le faire sur papier ou en utilisant soit un logiciel sur le web comme lucidchart, draw.io, etc., soit un logiciel sur votre desktop comme modelio, umbrello, etc. Libre à vous d’utiliser l’outil qui vous paraît le mieux.
Diagramme de classes (Class diagram)
Le diagramme de cas d’usage nous permet d’y voir un peu plus clair dans le fonctionnement du jeu. On peut maintenant s’intéresser aux classes qui vont nous permettre de réaliser toutes les actions.
Une vue « conceptuelle » des classes et de leurs relations :
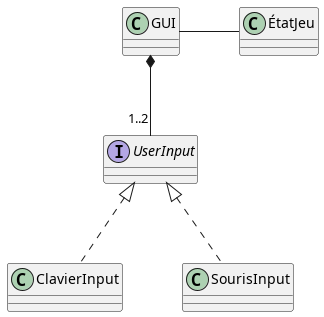
Le joueur n’interagit qu’à travers une interface graphique. Celle-ci récupère les commandes du joueur via un clavier, une souris, etc. Elle affiche l’écran d’accueil, la page de création du personnage et de connexion et, lorsque le jeu est lancé, l’état du jeu. L’état du jeu lui-même devrait être une classe à part entière dont le but est uniquement de conserver l’état du jeu, c’est-à-dire les positions du joueur, des coffres et des ennemis, des points de vie du joueur et des ennemis, etc.
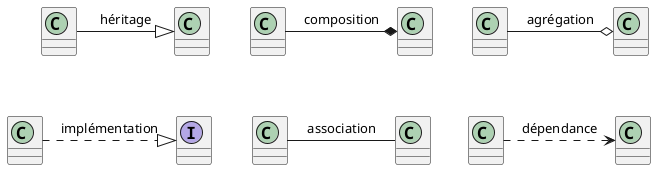
Cela suggère de créer une classe GUI, une classe ÉtatJeu ainsi que deux classes ClavierInput et SourisInput pour récupérer les commandes du joueur. En UML, les classes, classes abstraites et interfaces sont représentées par des rectangles. On peut imaginer que l’API est la même pour interroger les devices d’entrée/sortie clavier et souris. Dans ce cas, on crée une interface UserInput contenant cette API, et ClavierInput et SourisInput implémentent (on dit aussi réalisent) cette interface. En UML, on représente l’implémentation via une flèche en pointillés dont la tête est un triangle, cf. le diagramme ci-dessous. Évidemment, une instance de GUI doit contenir une instance de ClavierInput et/ou de SourisInput. Cette relation est une composition car cela n’aurait aucun sens que le clavier et la souris existent quand l’interface graphique du jeu est détruite. En UML, on représente la relation de composition via une flèche en traits pleins dont la tête est un losange noir. On représente la relation d’agrégation de la même manière à ceci près que le losange est blanc.
Pour que l’interface graphique GUI puisse afficher l’état du jeu, elle doit demander à ÉtatJeu de lui communiquer son état. Il existe donc une relation (on parle d'association) entre ces deux classes. ÉtatJeu n’est pas vraiment un « composant » de l’interface graphique, il ne serait donc pas logique de créer une relation de composition ou d’agrégation entre ces deux classes. Si une relation n’est ni de l’agrégation ni de la composition, on parle simplement d'association si la relation est bi-directionnelle ou bien de dépendance si elle est uniquement mono-directionnelle. Ici, si on considère qu’ÉtatJeu peut envoyer des signaux à GUI pour l’obliger à rafraichir la fenêtre de jeu, on utilisera une association, sinon seule GUI enverra des messages à ÉtatJeu et on aura une dépendance. On va supposer ici que c’est la première solution qui est retenue pour notre jeu. En UML, une association est représentée par une arête en traits pleins. Les dépendances sont représentées par des flèches en pointillés dont la tête est un >. Enfin, pour toutes ces relations (association, dépendance, composition, agrégation), on peut indiquer à côté de l’arête/la flèche le nombre d’instances impliquées (lorsqu’il ne s’agit que d’une seule instance, on n’indique pas le nombre). Par exemple, GUI peut contenir uniquement un clavier, uniquement une souris ou les deux, on indiquera donc une cardinalité « 1..2 ». On peut préciser que l’on peut avoir un nombre arbitraire d’instances en utilisant la cardinalité *. Cela nous amène donc au diagramme de classe suivant :
On peut maintenant détailler le contenu de la classe ÉtatJeu. ÉtatJeu contient l’état du Joueur, des Coffres ainsi que des Orcs, Gobelins et Elfs. Ici, les relations sont de composition. Mais, pour respecter les principes SOLID, on ne doit pas stocker directement dans ÉtatJeu une liste d’Orcs, de Gobelins ou d’Elfs car rajouter un nouveau type d’ennemi impliquerait de modifier ÉtatJeu (donc une violation du principe Ouvert/Fermé). On crée donc une interface ou une classe abstraite Ennemi qui représentera n’importe quel type d’ennemi et ÉtatJeu contiendra une liste d’Ennemi. On peut imaginer que certaines propriétés (position, points de vie, etc.) sont communs à tous les types d’ennemis. Donc, ici, une classe abstraite paraît plus appropriée. C’est ce que reflète le diagramme ci-dessous.
Pour savoir s’il est proche d’un Ennemi, le Joueur peut demander (via une méthode) à l’Ennemi sa position, et réciproquement. Puisque l’interaction est bidirectionnelle, on a ici une association (une composition ou une agrégation n’aurait aucun sens). L’intérêt de préciser ce type de lien réside dans le fait qu’on peut anticiper qu’un changement d’API dans l’une de ces classes peut nécessiter des changements dans l’autre. Il y a également une relation entre le Joueur et les Coffres : le Joueur pourra demander à voir le contenu d’un Coffre, mais le Coffre ne demandera jamais rien au Joueur. Dans ce cas, la relation est asymétrique et il s’agit donc d’une dépendance.
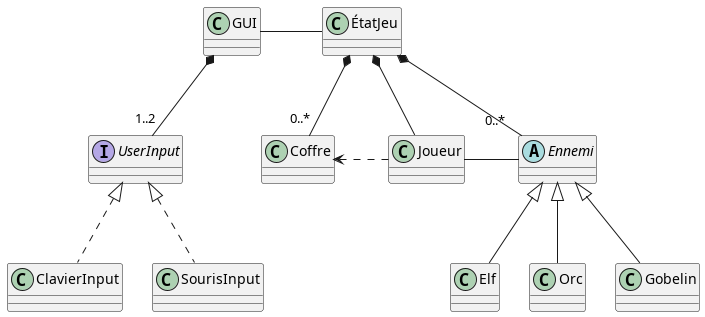
Notez que ce sont surtout l’héritage, la composition et l’agrégation qui sont importantes, puisque ces relations auront un impact très concret sur vos classes. Les associations et les dépendances ont surtout un intérêt pour voir l’impact de modifications dans les API (signatures des méthodes) quand vous ferez de la maintenance/mise à jour de votre application.
L’architecture ci-dessus semble permettre de réaliser toutes les actions répertoriées dans le diagramme de cas d’usage. Par exemple, l’action « se connecter » revient à ce que le joueur interagisse avec GUI pour sélectionner, dans un menu, l’item de connexion. GUI demande alors à ÉtatJeu de s’initialiser. Ce dernier crée les Ennemis et les Coffres et initialise l’instance de Joueur. GUI peut alors afficher l’état du jeu. On peut de manière similaire déterminer les processus impliqués par les autres actions.
Résumé des entités et relations d'un diagramme de classes
Voici une résumé de la notation graphique des diagrammes de classes. Tout d’abord, les entités les plus utilisées (classes, classes abstraites, interfaces) que l’on peut trouver :

Les relations les plus utilisées :
Niveaux de détails des classes
On peut grossièrement scinder en 3 le niveau de détails des classes que l’on affiche :
Niveau conceptuel : représente les concepts du domaine, de la classe (cf. le diagramme ci-dessus),
Niveau spécification : on se focalise sur l’API, l’interface de la classe ainsi que sur les attributs importants de la classe,
Niveau implémentation : on décrit tous les attributs et les méthodes que l’on n’avait pas listés dans le niveau « spécification » mais qui sont nécessaires à sa réalisation.
Le diagramme de classes montré plus haut est clairement de niveau conceptuel. Si l’on considère les deux autres niveaux, il faut décrire plus précisément le contenu des classes, classes abstraites et interfaces.
Prenons comme exemple la classe Joueur. Un joueur a un état (position en x,y, points de vie, quantité de munitions, etc.). Il est pourvu de méthodes pour se déplacer, changer de direction, prendre le contenu d’un coffre, attaquer un ennemi. Dans le niveau « spécification », on pourrait donc avoir une classe similaire à celle ci-dessous :

On voit que la « boite » correspondant à une classe est scindée verticalement en trois blocs : on a tout d’abord le nom de la classe, puis la liste des attributs et, enfin, les méthodes. Pour les attributs, il est d’usage d’indiquer leur type (mais ce n’est pas obligatoire). En général, on n’indique pas le type de retour des méthodes ni leurs paramètres (mais on peut le faire si on veut). On n’indique pas non plus les constructeurs (ni le destructeur si l’on est en C++). Notons que sur la gauche des attributs et méthodes, on indique leur visibilité :
| signe | Signification |
|---|---|
| + | attribut/méthode « public » |
| - | attribut/méthode « private » |
| # | attribut/méthode « protected » |
| ~ | attribut/méthode « package-private » |
Les méthodes et classes abstraites sont en principe écrites en italique. Les méthodes statiques sont représentées en les soulignant. Les méthodes statiques abstraites ne sont pas représentées… Ah ah, évidemment puisque ce type de méthode n’existe pas !
Le niveau « implementation » est identique à celui de « spécification », excepté que l’on donne plus de détails : il s’agit de préciser la totalité des attributs et des méthodes.
Un exemple de diagramme de classe plus détaillé
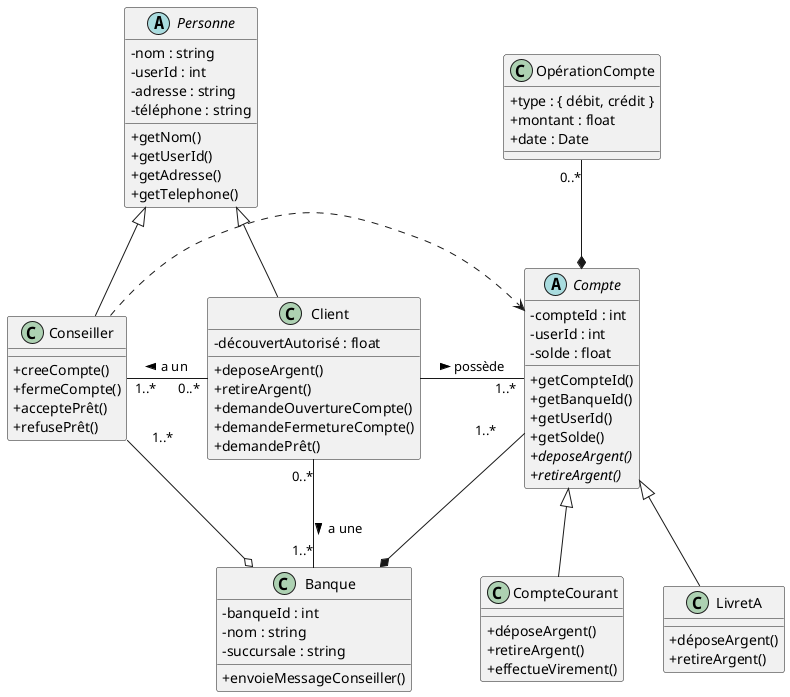
Le diagramme ci-dessous représente une application de gestion bancaire. La Banque est constituée de Conseillers et de Comptes clients. En ce qui concerne les Conseillers, il y a une agrégation car, si la Banque ferme, les Conseillers peuvent se faire embaucher dans une autre Banque. En revanche, en cas de fermeture de la banque, les comptes clients sont détruits. Les clients sont des Personnes qui peuvent être clients dans une ou plusieurs Banques. Ici, la relation entre Banque et Client n’est pas une relation de composition ou d’agrégation mais plutôt une relation « une Banque possède des Clients » ou « un Client a une Banque ». On peut indiquer la signification de l’association sur l’arête (ici, « a une »), avec un triangle qui spécifie la direction de cette relation (ici, c’est le Client qui a une Banque). C’est le Client qui « possède » un Compte, etc. Un compte peut être un compte client classique ou bien un compte d’épargne comme un Livret A. Les règles de dépôt et de retrait sont différentes (si vous déposez de l’argent le 3 du mois sur un Livret A, il sera crédité au 15 du mois par exemple). D’où l’idée d’hériter d’une classe abstraite Compte. Cette classe contient la liste des operations bancaires du compte (OpérationCompte). Cela nous amène naturellement au diagramme ci-dessous :
Exercice 2 : Ma petite entreprise, la classe...
Écrivez le diagramme de classe de l’application de votre entreprise de restauration en ligne.
.